在当今数字化的时代,视频内容的需求日益增长。无论是电影、电视剧、综艺节目还是其他类型的视频,人们都希望能够方便地获取到自己感兴趣的资源。而对于一些特定的视频资源,如小电影,有时候我们可能需要通过爬虫技术来获取。将介绍如何使用 PYTHON 编写爬虫程序,轻松爬取各类小电影网站上的视频资源。
准备工作
在开始编写爬虫程序之前,我们需要做好以下准备工作:
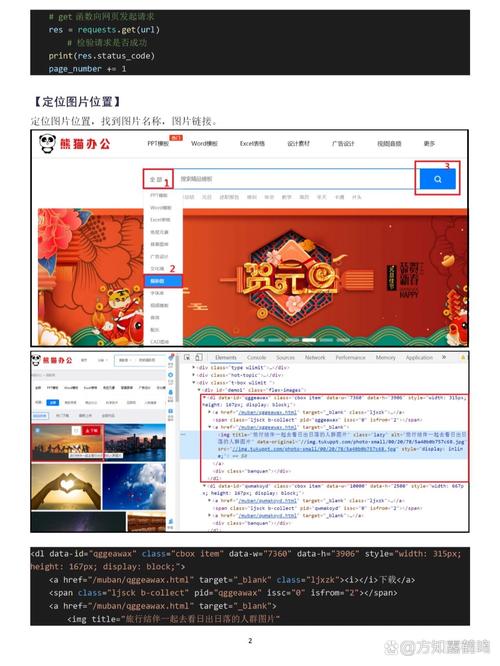
1. 选择一个合适的小电影网站:我们需要选择一个合法合规的小电影网站。确保你选择的网站不会侵犯版权,并且遵守相关的法律法规。
2. 了解网站的结构和规则:在开始爬取之前,我们需要了解目标网站的结构和规则。这包括了解网站的页面布局、视频的链接格式、请求方式等信息。
3. 安装必要的库:我们将使用 PYTHON 的`requests`库和`BeautifulSoup`库来发送请求和解析页面。可以使用以下命令安装这些库:
```
pip install requests
pip install beautifulsoup4
```
爬虫程序的编写
接下来,我们可以开始编写爬虫程序了。以下是一个简单的示例代码,演示如何爬取小电影网站上的视频资源:
```python
import requests
from bs4 import BeautifulSoup
# 定义目标网站
target_url = "
# 发送 GET 请求获取页面内容
response = requests.get(target_url)
# 解析页面内容
soup = BeautifulSoup(response.text, "html.parser")
# 查找视频链接
video_links = soup.find_all("a", href=True)
# 提取视频链接
video_urls = [link.get("href") for link in video_links if "video" in link.get("href")]
# 打印视频链接
for url in video_urls:
print(url)
```
在上述代码中,我们首先使用`requests.get()`方法发送 GET 请求获取目标网站的页面内容。然后,使用`BeautifulSoup`库解析页面内容,并使用`find_all()`方法查找所有带有`href`属性的`a`标签。通过检查`href`属性中是否包含`video`关键字,我们提取出视频链接。打印出提取到的视频链接。
请注意,这只是一个简单的示例代码,实际的爬虫程序可能需要更复杂的逻辑和错误处理机制。还需要注意以下几点:
1. 处理反爬虫机制:一些网站可能会设置反爬虫机制,例如限制请求频率、检测 User-Agent 等。我们需要根据具体情况采取相应的措施来绕过这些限制。
2. 处理动态如果目标网站使用了动态加载技术来显示视频内容,我们可能需要使用`Selenium`等库来模拟浏览器行为,以获取完整的视频页面内容。
3. 合法性和道德准则:在爬取视频资源时,务必遵守相关的法律法规和道德准则。确保你有合法的授权或使用方式来获取这些资源。
4. 数据存储和处理:根据实际需求,我们可能需要将爬取到的视频链接存储到数据库或文件中,以便进一步处理和下载视频。
通过使用 PYTHON 的`requests`库和`BeautifulSoup`库,我们可以轻松地编写爬虫程序来爬取小电影网站上的视频资源。在进行爬虫操作时,我们必须遵守法律法规和道德准则,并注意处理反爬虫机制和动态内容。也要尊重网站的版权和使用规则,不要将爬取到的视频用于非法或不道德的目的。
希望能够帮助你了解如何使用 PYTHON 爬虫技术获取小电影网站上的视频资源。在实际应用中,根据具体情况进行适当的调整和改进,以满足你的需求。

